Instalar y configurar CEPH en Proxmox
En el siguiente post, Proxmox y Ceph de 0 a 100 parte III, abordaremos la instalación y configuración de Ceph en Proxmox.
Antes de nada tenemos que saber que Ceph es un sistema de archivos distribuido libre, escalable, de alto rendimiento y robusto, diseñado para no tener ningún punto de fallo, libre de errores y tolerante a fallos. En una infraestructura tenemos que conocer los elementos que conforman un cluster Ceph:
Monitores del cluster (ceph-mon) que son los encargados de mantener y gestionar la actividad en los nodos, vigilando los componentes manager service, object storage server y metadata server para poder conseguir el objetivo de Ceph. En todo cluster de producción, lo mínimo es tener tres monitores, por lo tanto en nuestro laboratorio, los tres nodos serán Monitores de nodos.
Manager, el encargado de gestionar la utilización del espacio, métricas y estado del cluster. Por lo menos 2 de los nodos tienen que tener este rol.
OSD (object storage daemon) , responsables del almacenamiento, duplicado y restauración. Al igual que con los monitores se recomiendan un mínimo de 3.
Servidor de metadatos, el cual almacena como su nombre indica metadatos y permite comandos básicos de POSIX filesystem. Nos permitiría crear un CephFS..
Ceph no sería posible sin su algoritmo CRUSH, el cual determina cómo almacenar y recuperar datos calculando las ubicaciones de almacenamiento de datos, es decir, requiere un mapa de su cluster el cual contiene una lista de OSD y reglas para saber como debe replicar los datos, utilizando el mapa para almacenar y recuperar datos de forma pseudoaleatoria en OSD con una distribución uniforme de datos en todo el cluster.
Respecto a los requisitos, tenemos que tener en cuenta:
Crear un OSD por disco
Asignar un subproceso por OSD, es decir, un hilo o thread.
Dimensionar la RAM en una relación mínima de 1 GB por TB de almacenamiento en disco en el nodo OSD
Para producción disponer de tarjetas de 10 Gigabits
Comentado todo lo anterior pasemos a la instalación y configuración. Una vez logueados en nuestro cluster comencemos por PVE1 en el apartado CEPH, donde nos indica un cartel que Ceph no está instalado y si nos gustaría instalarlo ahora.
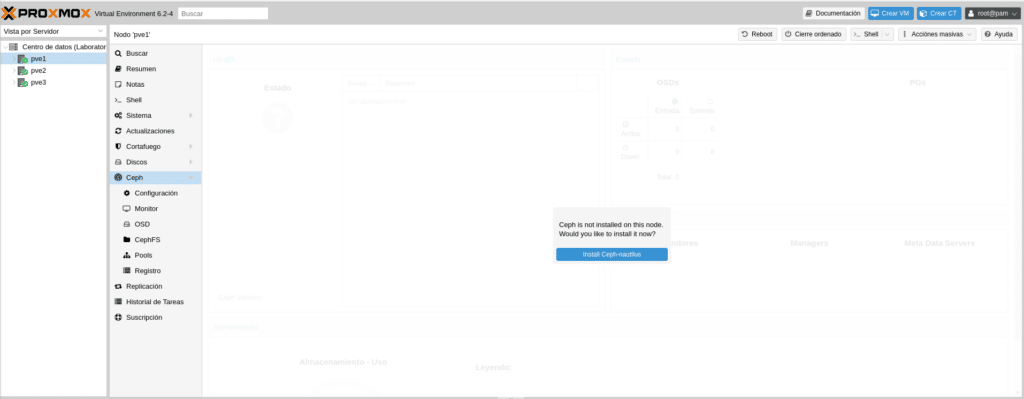
Hacemos click en Install Ceph-nautilus y nos mostrara una pequeña info de que es CEPH y un enlace a la documentación.
Hacemos click en estart installation y tras unos segundos obtendremos.
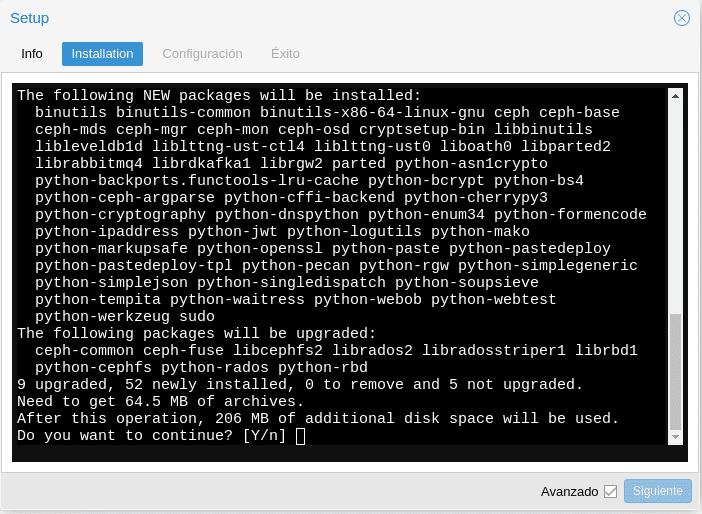
Le decimos "Y" y esperamos a que termine y ponga Installed ceph nautilus successfully, para dar a siguiente.
En la siguiente pantalla que nos encontramos está la configuración
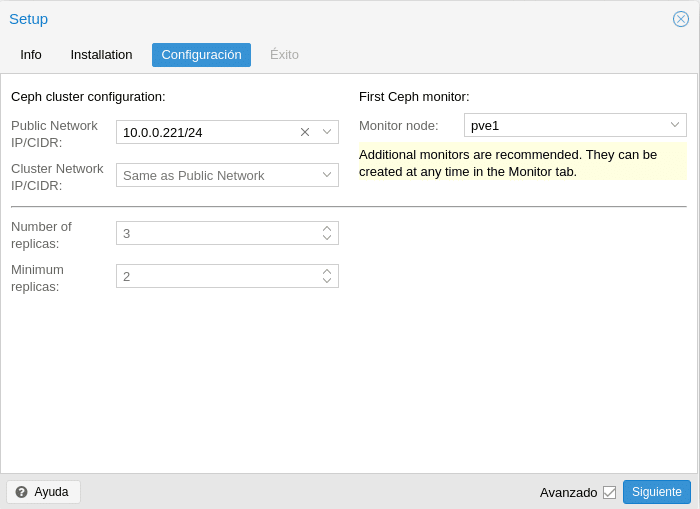
En esta primera parte nos puede llamar la atención, public network y cluster network, donde en la propia documentación de Ceph nos dicen que utilizar una red publica y un de cluster nos complicaría la configuración tanto de hardware como de software y no suele tener un impacto significativo en el rendimiento, por lo tanto es mejor tener un bond de tarjetas para que las NIC estén en activo/activo y configuremos que ambas redes son la misma red, es decir, simplemente en la Public Network seleccionamos nuestra interfaz interna, en este caso la 10.0.0.221/24 y en Cluster Network "Same as Public Network", pero si queremos ser finos y lo separamos en estas 2 redes, por la Red de cluster iría la replicación OSD y el tráfico de latidos y por la Pública el resto de tráfico de Ceph.
En la parte de réplicas configuraremos el número de réplicas que tendremos de cada objeto, a mayor número de réplicas, mayor espacio consumido pero aumentaremos el número de fallos permitidos. Respecto al Minimum replicas establece el número mínimo de réplicas requeridas para I/O, es decir, cuantas tienen que estar bien para tener acceso a los datos, si ponemos 3 en Número de réplicas y Minimum 3, en cuanto una réplica se caiga dejaremos de tener acceso a los datos por lo tanto mínimo tenemos que poner una menos para que todo siga funcionando. Tener en cuenta a la hora de configurar que siempre podrás aumentar el número de réplicas más adelante, pero no podrás disminuir, tendrás que crear un pool nuevo, mover los datos y luego borrar el antiguo para poder reducir el número de réplicas.
Y por último como es el primer Ceph monitor nos indica que más monitores son recomendados, de hecho como os digo mínimo 3 en producción para no tener problemas, le damos a crear y en la siguiente pantalla a Finalizar.
Una vez terminado esta parte nos vamos al apartado OSD y hacemos click en Crear: OSD para añadir nuestros OSD
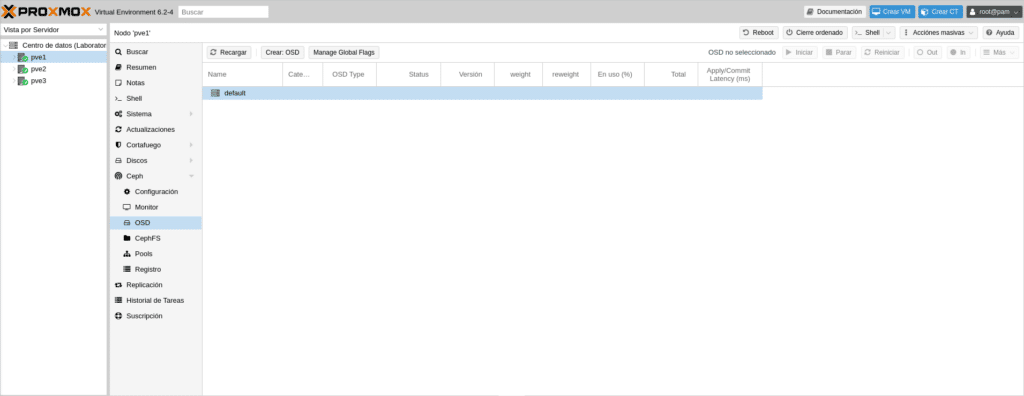
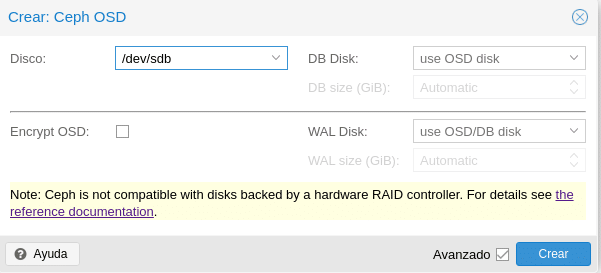
Se observa que Ceph nos advierte que no es compatible con Raid por Hardware y un enlace con más detalles.
En disco seleccionamos el disco que vamos a utilizar en este caso el que tenemos de 40 GB. Luego tenemos 2 campos DB Disk y WAL Disk, antes Ceph Luminous usaba Filestore como almacenamiento predeterminado para los OSD de Ceph. A partir de Ceph Nautilus Proxmox ya no admite la creación de OSD filestore, aunque se puede seguir creando por consola usando el comando ceph-volume. Ahora utiliza Bluestore el cual necesita ambos parámetros, DB para los metadatos internos y WAL para el internal journal o write-ahead, por lo que es recomendable como hemos indicado en varias ocasiones usar SSD. Podemos configurar el espacio dejando que lo administre automáticamente o bien estableciendo una cantidad, teniendo en cuenta que necesitaremos para DB un 10% del OSD y para WAL el 1% del OSD e incluso podemos seleccionar otro disco diferente. Respecto a Encrypt OSD como su nombre indica si queremos encriptarlos.
En este laboratorio lo dejaremos tal cual está en la imagen, configurar según el escenario y arquitectura que vayáis a realizar.
Repetimos los pasos para instalar CEPH con PVE2 y PV3, con la única diferencia, que en configuración nos dirá que la Configuration already initialized.
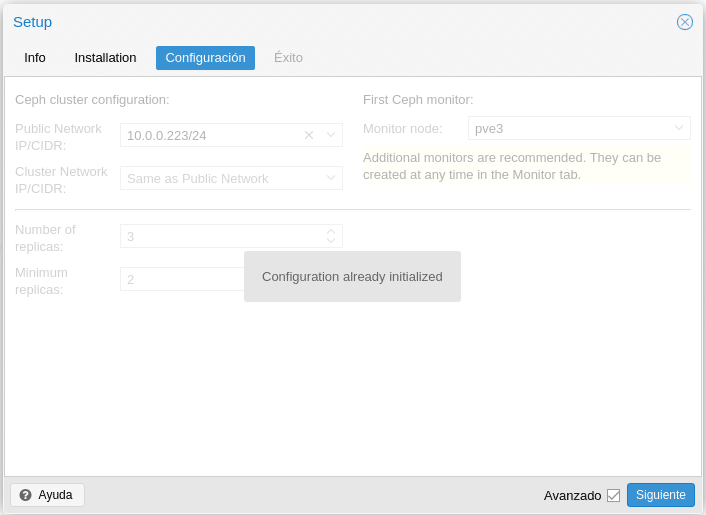
Le damos a siguiente y Finalizar. Nos dirigimos a PVE1/Ceph/Monitor y le damos a Crear
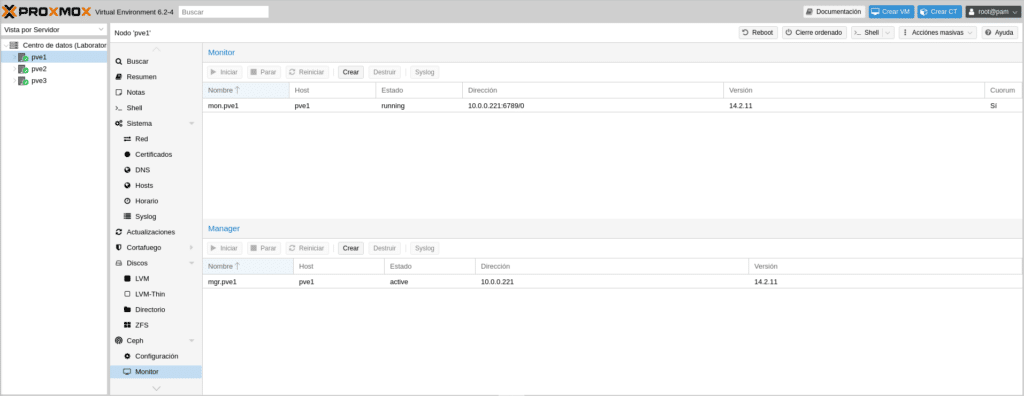
Seleccionamos PVE2 en la siguiente pantalla y crear
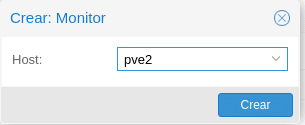
Repetimos para el PVE3 y hacemos lo mismo en Crear del apartado Manager para ambos nodos
Quedando así
A continuación tendremos que añadir los OSD del PVE2 y PVE3 siguiendo los pasos que realizamos para añadir el OSD del PVE1 dirigiéndonos al apartado Ceph/OSD de cada nodo, teniendo como resultado
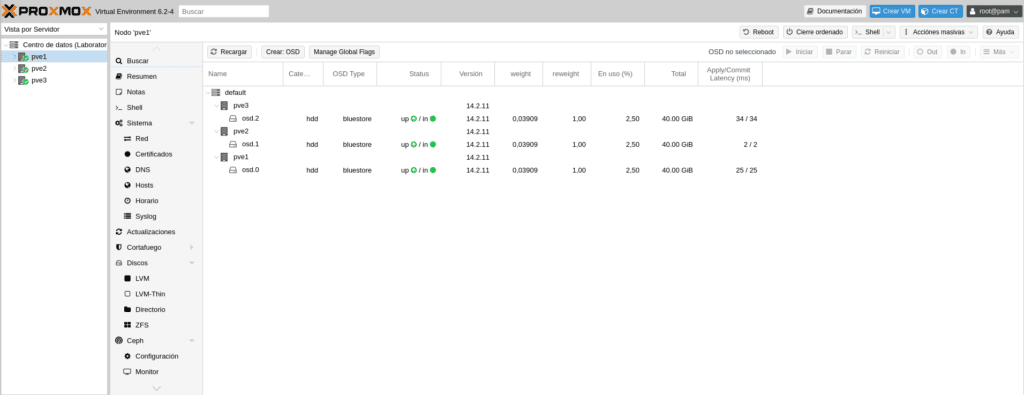
Ahora quizá venga lo más complicado de CEPH, las reglas de crush para hacer grupos de osd y poder montar los pools, por ejemplo si tenemos discos normales, ssd y nvram tendremos que crear 3 reglas o si tenemos todo SSD pero queremos hacer varios pools si tenemos 50 discos seleccionando los osd para cada pool.
Para ello tendremos que obtener el CRUSH Map decompilarlo, modificarlo y volver a compilarlo. Para ello nos dirigimos a la shell y tendremos que escribir lo siguiente:
Para obtenerlo
ceph osd getcrushmap -o {compiled-crushmap-filename}
Es decir,
ceph osd getcrushmap -o cephrulescompiled
Para decompilarlo
crushtool -d cephrulescompiled -o cephrules.txt

Editamos el fichero cephrules.txt y modificamos lo siguiente

Por esto otro por ejemplo

Es decir, definimos una clase. Ahora en la sección rules
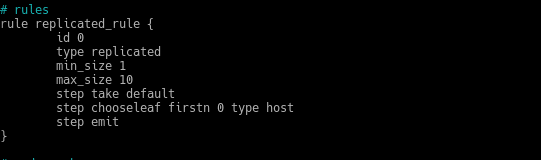
Creamos una nueva con otro nombre, otro id y en el step take default añadimos nuestra clase hddpool1, quedando así
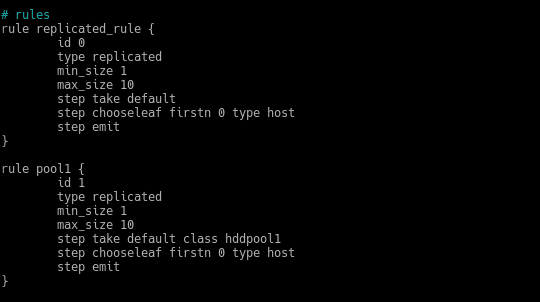
Lo siguiente sería recompilar con
crushtool -c cephrules.txt -o cephrulesnew
Y establecer el nuevo mapa
ceph osd setcrushmap -i cephrulesnew
Hecho esto si nos vamos a Ceph/OSD en la GUI observamos que en Categoría pondrá hddpool1
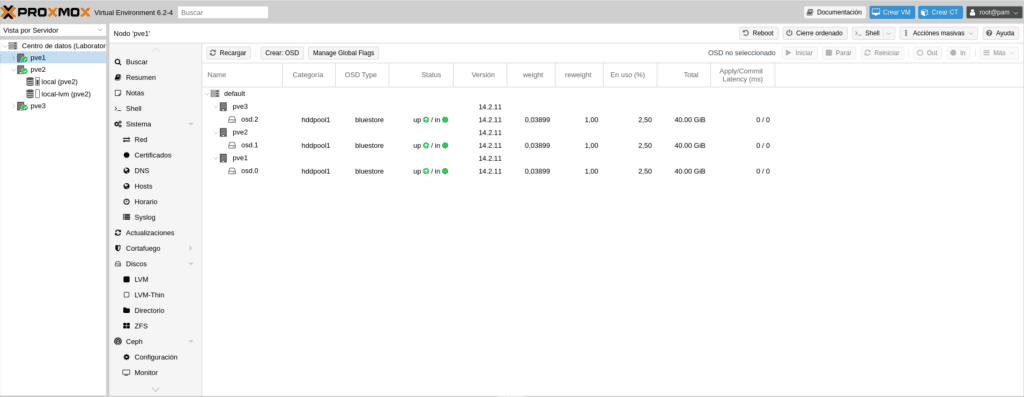
Como os he comentado quizá es de lo más complicado de Ceph aunque si te confundes editando porque te falte una { por ejemplo o por mala construcción no te dejará recompilar, eso sí, si en un entorno de producción te confundes en los OSD por ejemplo ya si que puede haber problemas.
El siguiente paso sería crear los pools donde irán almacenados los datos de las máquinas virtuales, nos dirigimos Ceph/Pools y pinchamos en crear
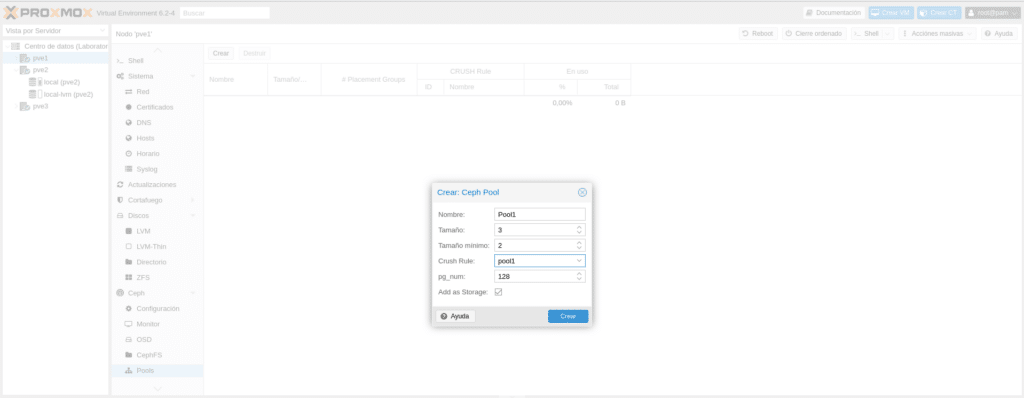
Tenemos que darle un nombre "Pool1″ para seguir nomenclatura, el Tamaño es el número de réplicas igual que vimos anteriormente y el tamaño mínimo es el mínimo de réplicas para I/O. Ahora bien os podéis preguntar en que se basan las réplicas, por Host o por OSD, es decir si ponemos 3, tendremos la original y dos más, pero en diferente Host u OSD. La respuesta a esta pregunta está en el mismo fichero de rules que hemos creado, en la sección types
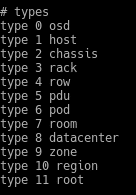
Tenemos todos estos tipos y en la regla definimos en que tipo estará basado
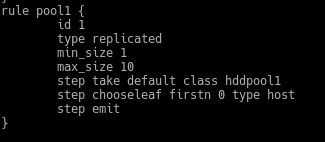
En este caso la hemos definido en host, por lo tanto tendremos la original y una copia en 2 hosts diferentes.
A continuación, en Crush rules seleccionamos la que hemos creado en el Mapa para el Pool1, que la hemos llamado Pool1 y el pg_enum que en versiones anteriores a Nautilus era la frustración de muchos, ya que elegir un valor incorrecto no siempre se podía corregir ya que se podía aumentar pero nunca disminuir. Este valor se calculaba con la fórmula (ODSs * 100)/Réplicas y teníamos que tener en cuenta que si lo aumentábamos más adelante, también debíamos aumentar el valor de pgp_num con el mismo valor de pg_num lanzando los siguientes comandos
ceph osd pool set {nombre del pool} pg_num {valor nuevo}
ceph osd pool set {nombre del pool} pgp_num {mismo valor de pg_num}
Con Nautilus este problema desaparece ya que se puede reducir y para olvidarse del todo podemos activar el pg_autoescaler desde la consola con
ceph mgr module enable pg_autoscaler
y comprobar el autoscale con
ceph osd pool autoscale-status
Por último dejamos marcada la casilla de "Add as Storage" para que nos cree el almacenamiento de tipo RDB y si lanzamos ahora el comando anterior, nos devolverá

Fíjense en el parámetro AUTOESCALE tenemos un warn, ¿que significa?, nada preocupante es el valor predeterminado en Nautilus para AUTOESCALE. Tenemos 3 posibles
off: inhabilita el ajuste de escala automático para este grupo. Depende del administrador elegir un número de PG apropiado para cada grupo.
on: habilita los ajustes automáticos del recuento de PG para el grupo dado.
warn: Genere alertas de salud cuando se deba ajustar el recuento de PG
Para cambiar nuestro pool1 a modo on y olvidarnos por completo, escribimos en la shell lo siguiente:
ceph osd pool set Pool1 pg_autoscale_mode on
Realizamos esto por cada pool que queramos, cambiando Pool1 por el nombre del pool. Estas serían las salidas por consola.

Como vemos han cambiado los datos y ha bajado el pg_num a 32 sin ningún problema cuando antiguamente no se podía.
Si nos vamos a la GUI en Centro de datos/Almacenamiento veremos que ya tenemos el Pool1 disponible para Imagen de disco y contenedores montado en los 3 nodos.
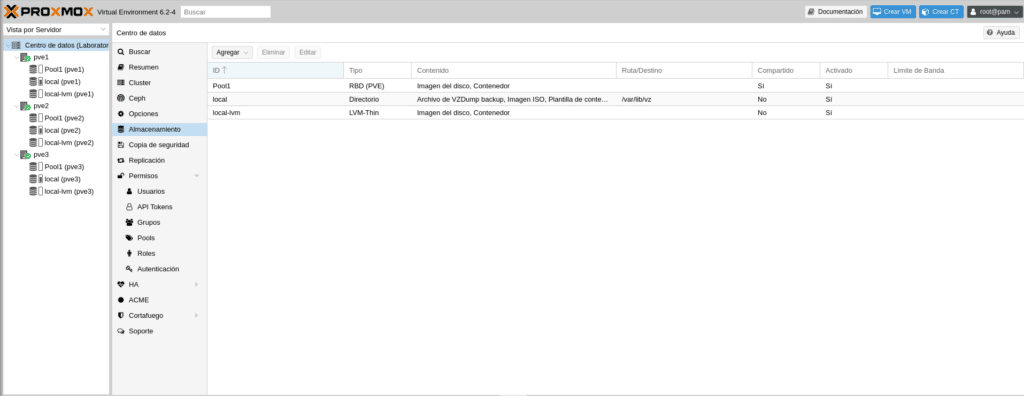
Hasta aquí tenemos montado nuestro cluster con HA y Ceph, en el siguiente post veremos como crear un grupo de HA, crear una vm, un contenedor y haremos pruebas de HA.
Espero les haya gustado, a disfrutar la vida. Si quieres adquirir alguna de las licencias ponte en contacto con nosotros, somos partner de Proxmox.
Continuar Proxmox y Ceph de 0 a 100 Parte IV
TL.
Gracias por leer nuestros posts.