Harvesting
Today we will talk and learn how to use a great tool created by Christian Martorella, which continues to evolve since it started back in 2014.
In a very simple way we can collect information (emails, names, subdomains, ips and urls) about companies from multiple public sources (google, duckduckgo, linkedin, … many, increasing).
This post is intended for those people who want to check that there is no data leakage about their companies or domains, i.e., for example, there are mails that should never be published to avoid being targets of phishing or social engineering, attacks that every day are more worked.
Its installation is very simple, it is more complex, depending on the distro used, to install the requirements than the application itself. For example, our laboratory machine is going to be a Debian 9 so that they can see difficulties that can be found. It is also necessary to say that we have pentesting distributions where it is already included.
The dependencies would be
- Python 3.7+
- python3 -m pip install pipenv
However, when we start it, we will see that it asks for more dependencies.
Where do we start?
It is clear, installing python3.7+ . In our Debian 9 we will have to perform the following steps:
-
- Install the packages needed to build the phyton source.
sudo apt update
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev curl python3-pip
-
- Download the latest version of python, I usually do it in /tmp so that it is deleted when I restart the computer.
curl -O https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tar.xz
-
- Unzip
tar -xf Python-3.7.7.tar.xz
-
- We enter the directory
cd Python-3.7.7
-
- and start the configure to check that all the dependencies are satisfied, we will also pass the –enable-optimizations parameter which will make the process take longer but will optimize the Python binary
./configure –enable-optimizations
-
- Once this process is finished, which will take more or less time depending on the hardware, we build it with
make -j 2
*Note: the -j flag will be set depending on your cores, as our lab virtual machine has 2, we have set 2, but if you have 8 set 8 to make it go faster.
-
- Now we only need to install it, where in order not to overwrite the python3 binaries, we will use
sudo make altinstall
Perfect, now we have everything we need to install theHarvester, where we can use git or download the zip. In this case we are going to do it by zip in case someone is not used to git and it gives some failure by curl versions or any reason.
We move to the directory where we want to install, for example, /opt would be a good location for this type of self-contained tools that do not follow standards.
sudo curl -LO https://codeload.github.com/laramies/theHarvester/zip/refs/heads/master
Unzip
sudo unzip master.zip
Its installation as you will see is to download the zip and unzip it, we enter into the directory
cd theHarvester-master
Now we have two options to start the application with Pipenv or without it, in both cases it is likely to give you an error because some module is missing, when you install that module it will ask you for another one until all the modules are installed, so to avoid going crazy execute the following commands
sudo pip3.7 install –upgrade pip
sudo pip3.7 install uvloop pyyaml aiohttp dnspython shodan aiodns aiosqlite plotly netaddr pysqlite3
- With pipenv, inside the directory where we have installed the program, we perform the following commands
sudo python3.7 -m pip install pipenv
sudo pipenv install
pipenv shell
python3.7 theHarvester.py -h
- Without pipenv
python3.7 -m pip install -r requirements/base.txt
python3.7 theHarvester.py -h
If you have followed up to here the process you will observe one of the many problems that we can find, in this case in Debian 9 built from the sources it is not going to find the sqlite3 module no matter how much we install it.
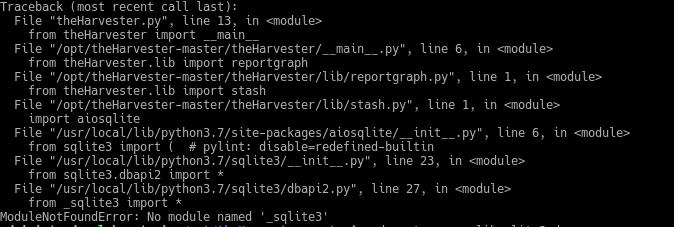
To do this we must recompile using
–enable-loadable-sqlite-extensions
but first install libsqlite3-dev
sudo apt install libsqlite3-dev
Therefore, we turn again to
cd /tmp/Python-3.7.7/
and we recompile with
./configure –enable-optimizations –enable-loadable-sqlite-extensions
And we return to build and install, now it will take much less time than the first time because as long as we do not restart since we are in /tmp only has to add the sqlite extensions.
make -j 2
sudo make altinstall
Now all we have to do is check that it does start up
cd /opt/theHarvester-master/
sudo python3.7 theHarvester.py -h
Voilá, here is the help
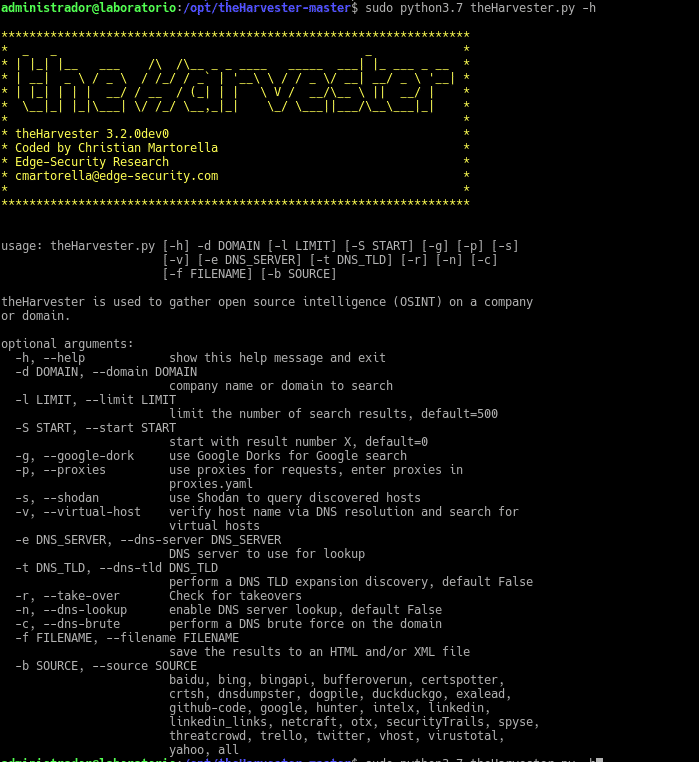
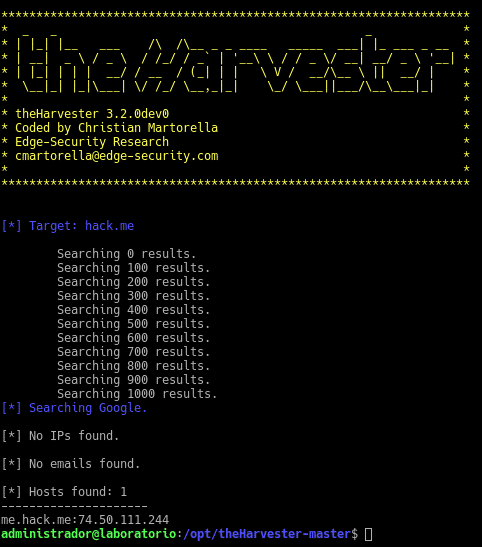
As we can see the help is very well explained and we can start harvesting information. Let’s see an example taking the information by console from the domain hack.me to not show information from more than other domains as this will only show us a host, with a limit of 1000 searches in the public source google
sudo python3.7 theHarvester.py -d hack.me -l 1000 -b google
We are going to do the same example but in addition to view it by console, we will save it in an xml and search in duckduckgo
sudo python3.7 theHarvester.py -d hack.me -l 1000 -b duckduckgo -f hackme.xml
This will also create an html called hackme.xml.html, if we open the html we will see the nicest data
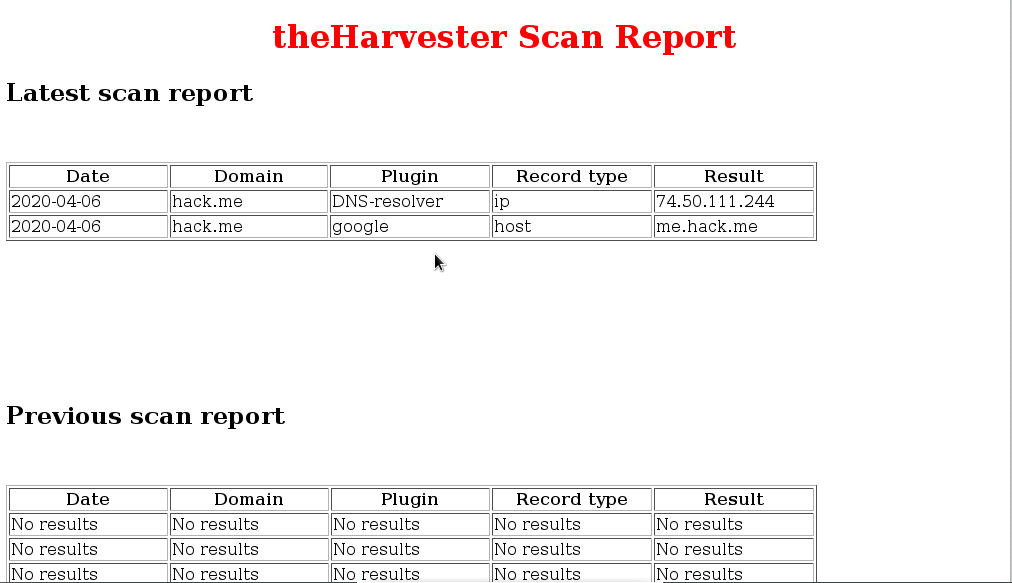

This is all I hope you are entertained.
Don’t use any of this post to do harm because karma is there…lurking in the shadows.
TL.