Cosechando
De una manera muy simple podremos recopilar información(emails,nombres,subdominios,ips y urls) sobre empresas desde múltiples fuentes públicas (google,duckduckgo,linkedin,…muchísimas, van aumentando)
Este post va dirigido para aquellas personas que quieren comprobar que no hay fuga de datos sobre sus empresas o dominios, es decir, por ejemplo hay mails que nunca deberían estar publicados para evitar ser objetivos de phising o ingeniería social, ataques que cada día están más trabajados.
Su instalación es muy sencilla, es más complejo según distro utilizada, instalar los requerimientos que la aplicación en sí. Por ejemplo, nuestra máquina de laboratorio va a ser un Debian 9 para que puedan ver dificultades que se puedan encontrar. También hay que decir que tenemos distribuciones de pentesting donde ya viene incluida.
Las dependencias serían
- Python 3.7+
- python3 -m pip install pipenv
De todas formas cuando lo arranquemos veremos que nos pide más dependencias
¿Por donde empezamos?
Está claro, instalando python3.7+ . En nuestro Debian 9 tendremos que realizar los siguientes pasos:
- Instalar los paquetes necesarios para construir la fuente de phyton.
sudo apt update
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev curl python3-pip
- Descargarnos la última versión de python, yo suelo hacerlo en /tmp para que se borre cuando reinicio el equipo
curl -O https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tar.xz
- Descomprimimos
tar -xf Python-3.7.7.tar.xz
- Entramos en el directorio
cd Python-3.7.7
- y arrancamos el configure para comprobar que todas las dependencias están satisfechas, además le pasaremos el parámetro –enable-optimizations el cual hará que el proceso tarde más pero optimizará el binario de Python
./configure –enable-optimizations
- Una vez finalizado este proceso que tardará más o menos dependiendo del hardware lo construimos con
make -j 2
*Nota: la bandera -j será ajustada en función de tus cores, como nuestra máquina virtual de laboratorio tiene 2, hemos puesto 2, pero si tienes 8 poner 8 para que vaya más rápido.
- Ya solo nos falta instalarlo, donde para no sobrescribir los binarios de python3 utilizaremos
sudo make altinstall
Perfecto, ya cumplimos todo lo necesario para instalar theHarvester, donde podemos utilizar git o bien descargarnos el zip. En este caso lo vamos hacer por zip por si alguien no está acostumbrado por git y le da algún fallo por versiones de curl o cualquier motivo.
Nos movemos al directorio donde queremos instalar, por ejemplo, /opt sería una buena ubicación para este tipo de herramientas auto contenidas que no siguen estándares.
sudo curl -LO https://codeload.github.com/laramies/theHarvester/zip/refs/heads/master
Descomprimimos
sudo unzip master.zip
Su instalación como veréis es descargarse el zip y descomprimir no tiene más, entramos dentro del directorio
cd theHarvester-master
Ahora tenemos dos opciones para arrancar la aplicación con Pipenv o sin él, en ambos casos es probable que os de error porque falta algún módulo, cuando instales ese módulo os pedirá otro hasta cumplir con todos, por lo tanto para evitar que os volváis locos ejecutar los siguientes comandos
sudo pip3.7 install –upgrade pip
sudo pip3.7 install uvloop pyyaml aiohttp dnspython shodan aiodns aiosqlite plotly netaddr pysqlite3
- Con pipenv, dentro del directorio donde hemos instalado el programa realizamos los siguientes comandos
sudo python3.7 -m pip install pipenv
sudo pipenv install
pipenv shell
python3.7 theHarvester.py -h
- Sin pipenv
python3.7 -m pip install -r requirements/base.txt
python3.7 theHarvester.py -h
Si habéis seguido hasta aquí el proceso observaréis uno de los muchos problemas que nos podemos encontrar, en este caso en Debian 9 construido desde las fuentes no va a encontrar el módulo sqlite3 por mucho que lo instalemos.
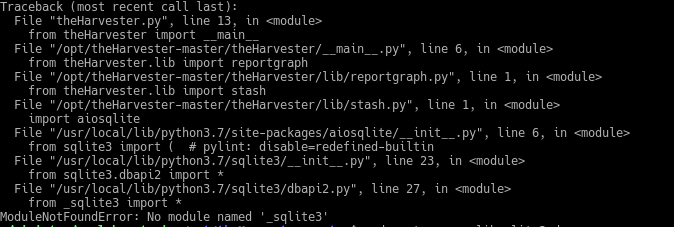
Para ello debemos recompilar utilizando
–enable-loadable-sqlite-extensions
pero antes instalar libsqlite3-dev
sudo apt install libsqlite3-dev
Por lo tanto nos dirigimos otra vez a
cd /tmp/Python-3.7.7/
y recompilamos con
./configure –enable-optimizations –enable-loadable-sqlite-extensions
Y volvemos a construir e instalar, ahora tardara muchísimo menos que la primera vez ya que mientras no reiniciemos puesto que estamos en /tmp solo tiene que añadir las extensiones de sqlite
make -j 2
sudo make altinstall
Ahora ya solo nos queda comprobar que ahora si arranca
cd /opt/theHarvester-master/
sudo python3.7 theHarvester.py -h
Tachán, aquí tenemos la ayuda
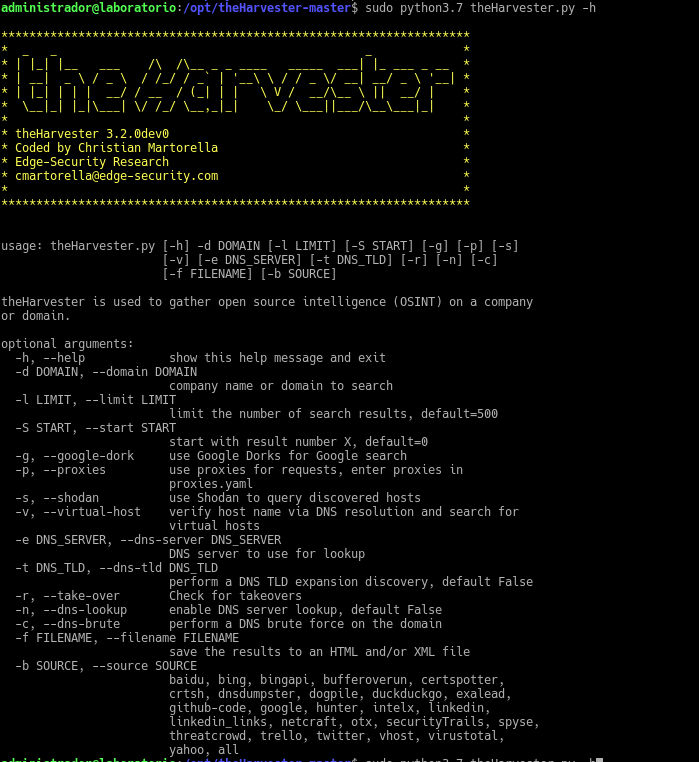
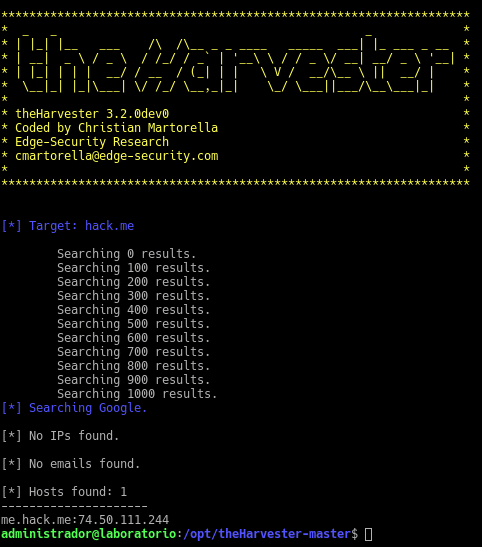
Como podemos ver la ayuda está muy bien explicada y ya podemos empezar a cosechar información. Vamos a ver un ejemplo sacando la información por consola del dominio hack.me para no mostrar información de más de otros dominios ya que este solo nos va a mostrar un host, con un límite de búsquedas de 1000 en la fuente pública google
sudo python3.7 theHarvester.py -d hack.me -l 1000 -b google
Vamos a realizar el mismo ejemplo pero además de verlo por consola, lo guardaremos en un xml y buscaremos en duckduckgo
sudo python3.7 theHarvester.py -d hack.me -l 1000 -b duckduckgo -f hackme.xml
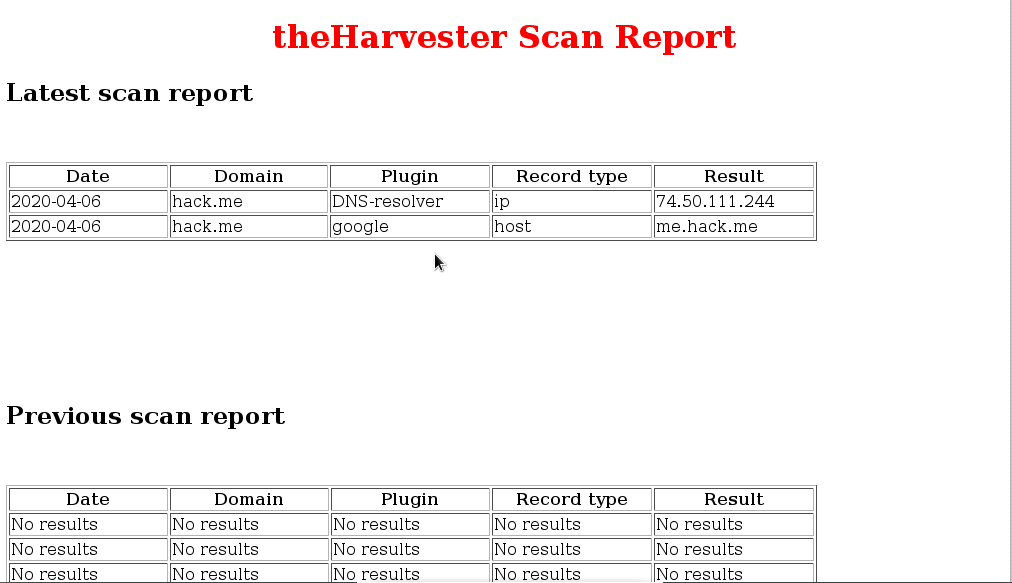
Esto creará también un html llamado hackme.xml.html, si abrimos el html veremos los datos más bonitos

Esto es todo espero que se entretengan.
No utilicen nada de este post para hacer daño porque el karma está ahí…acechando en las sombras.
TL.
Gracias por leer nuestros posts.