OLLAMA Y OPEN-WEBUI
Hace tiempo que no escribimos nada por falta de tiempo, pero hemos sacado un hueco para que tengas tu guía montar un chatgpt.
Para ello utilizaremos Ollama una herramienta para trabajar con modelos de lenguaje LLM o lo que es lo mismo modelos de lenguaje de gran tamaño. Junto con Open-WebUI, una interfaz de inteligencia artificial extensible, tendrás tu propio chatgpt ya sea en local o en tu propio servidor.
La instalación es sencilla, podemos utilizar docker si lo deseamos, aunque en esta guía será estilo tradicional para aquellos que aún tienen dificultados con docker.
Esta instalación la haremos en un Debian 12 con 6 cores y 16GB RAM y 100Gb de disco con modelos de lenguaje que no consuman más de eso. Nos dirigimos a nuestra consola de nuestra máquina ya sea local o por ssh. En nuestro caso todos nuestros laboratorios, formaciones, tutoriales,…las realizamos en MV de Proxmox.
Comencemos, conectados a nuestra máquina Debian 12 para este post y ejecutamos los siguientes comandos
Herramientas necesarias
apt-get install curl
Instalación de Ollama
curl -fsSL https://ollama.com/install.sh | sh
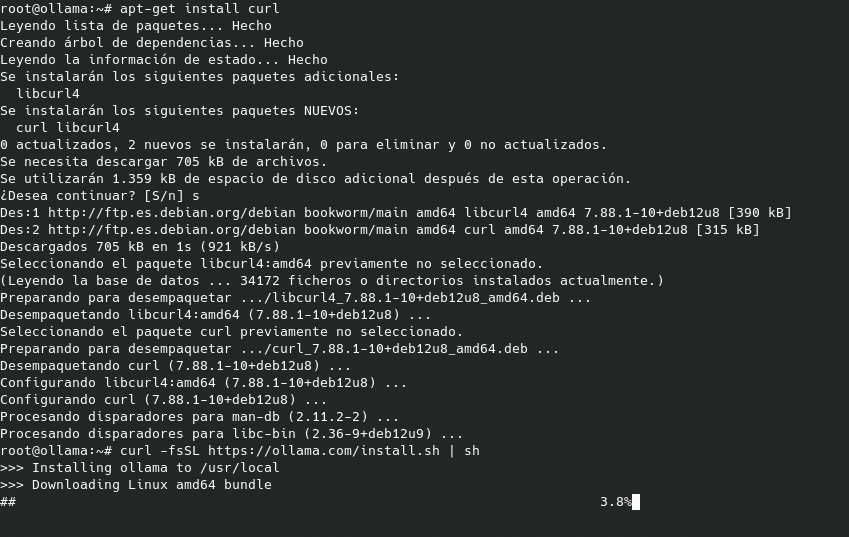
Una vez instalado, veremos que nos ha creado el servicio ollama.service escuchando en el puerto 11434 en localhost, el cual podemos editar si deseamos que se pueda acceder desde otros hosts
nano /etc/systemd/system/ollama.service
teniendo que añadir en la parte de [Service]
Environment="OLLAMA_HOST=0.0.0.0″
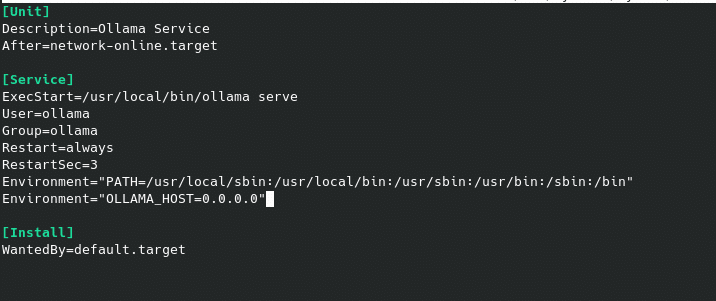
Recargamos y reiniciamos el servicio.
systemctl daemon-reload && systemctl restart ollama.service
Y comprobamos que está escuchando en cualquier interface.
ss -napt | grep ollama

Perfecto, ya tenemos nuestro Ollama instalado pero nos hace falta cargar los modelos, los cuales podéis ver en https://ollama.com/search y los cargaremos con ollama pull modelo. Tener en cuenta que necesitaréis bastante disco y memoria según los modelos cargados. Esta sería la memoría necesaria libre en el servidor para llama de Meta por ejemplo:
- Los modelos 7b generalmente requieren al menos 8 GB de RAM
- Los modelos 8b y 13b generalmente necesitan 16 GB de RAM
- Los modelos 70b generalmente requieren al menos 64 GB de RAM
En este laboratorio al ser una máquina pequeña para IA vamos a cargar un model 8b con:
ollama pull llama3.1:8b

Una vez lo tenemos descargado podemos arrancarlo y empezar usarlo con:
ollama run llama3.1:8b

Ya tenemos nuestro Ollama, ahora vamos a ponerle una interfaz gráfica, para lo cual utilizaremos Open-WebUI y crearemos un entorno Python.
Instalamos nuestro entorno:
apt-get install python3-venv
python3.11 -m venv /opt/openwebui
Activamos el entorno
source /opt/openwebui/bin/activate
Instalamos open-webui, la cual tardará un poco dependiendo de tu conexión.
pip install open-webui
Una vez termine arrancamos open-webui
open-webui serve
Y accedemos por la url http://localhost:8080/ o bien como es nuestro caso ya que está en otra máquina http://192.168.1.85:8080

Y empezamos el wizard
Una vez que ya estas dentro vereis que tenemos el model por defecto y nuestro llama3.1:8b ya que está por el puerto por defecto 11434 en la misma máquina
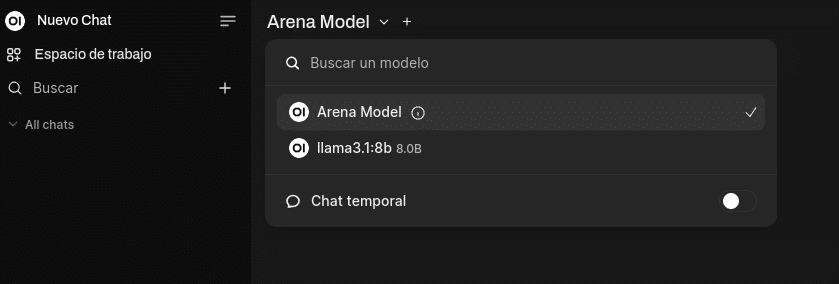
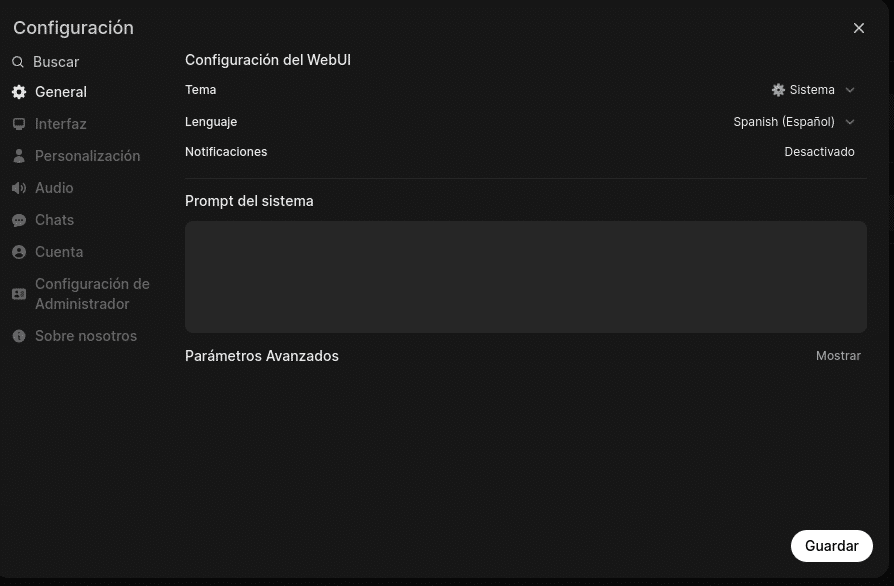
Si nuestro server de Ollama estuviera en otra máquina tendríamos que añadirlo en Configuración/Configuración de Administrador
Y dentro en conexiones, donde también podemos configurar OpenAI con tu clave API, teniendo en cuenta que tiene coste.
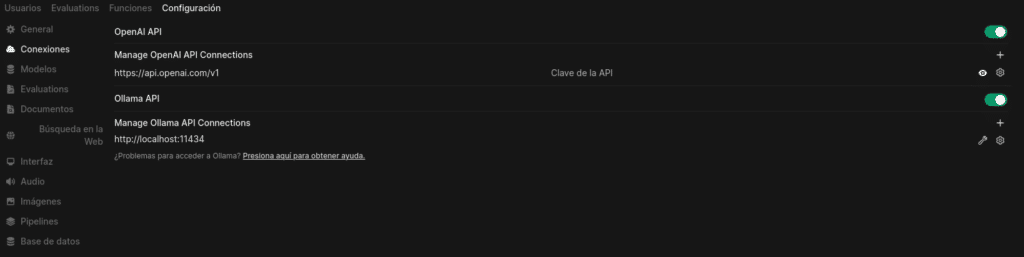
Desactivar si no lo vais a usar para que no intente consultar a OpenAI porque si está activa lo intentará dando errores 500 en vuestro log.

Esto es solo el comienzo de un mundo muy amplio.
TL.
Gracias por leer nuestros posts.