OLLAMA Y OPEN-WEBUI
It’s been a while since we wrote anything due to lack of time, but we have taken a moment to give you your guide to setting up a chatgpt.
To do this we will use Ollama, a tool to work with LLM language models or in other words, large language models. Together with Open-WebUI, an extensible artificial intelligence interface, you will have your own chatgpt either locally or on your own server.
The installation is simple, we can use docker if we want, although in this guide it will be traditional style for those who still have difficulties with docker.
We will do this installation on a Debian 12 with 6 cores and 16GB RAM and 100Gb of disk with language models that do not consume more than that. We go to our machine’s console either locally or by ssh. In our case all our laboratories, training, tutorials,…we do them in Proxmox VM.
Let’s start by connecting to our Debian 12 machine for this post and running the following commands
Tools needed
apt-get install curl
Installing Ollama
curl -fsSL https://ollama.com/install.sh | sh

Once installed, we will see that it has created the ollama.service service listening on port 11434 on localhost, which we can edit if we want it to be accessible from other hosts
nano /etc/systemd/system/ollama.service
having to add in the [Service] part
Environment=”OLLAMA_HOST=0.0.0.0″
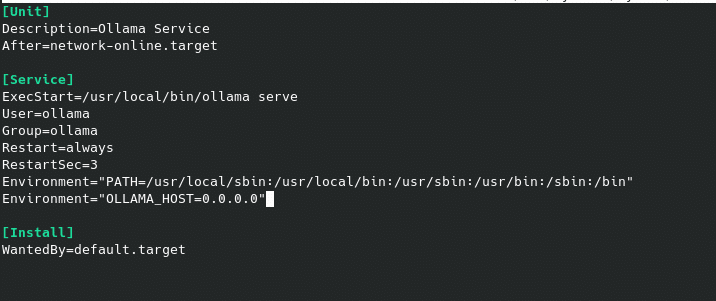
We reload and restart the service.
systemctl daemon-reload && systemctl restart ollama.service
And we check that it is listening on any interface.
ss -napt | grep ollama

Perfect, we already have our Ollama installed but we need to load the models, which you can see at https://ollama.com/search and we will load them with ollama pull model. Keep in mind that you will need a lot of disk and memory depending on the loaded models. This would be the free memory required on the server for a Meta llama, for example:
-
- Models 7b generally require at least 8 GB of RAM
- Models 8b and 13b generally need 16 GB of RAM
- Models 70b generally require at least 64 GB of RAM
In this lab, being a small machine for AI, we are going to load a model 8b with:
ollama pull llama3.1:8b

Once we have it downloaded, we can start it and start using it with:
ollama run llama3.1:8b

We already have our Ollama, now we are going to put a graphical interface on it, for which we will use Open-WebUI and create a Python environment.
We install our environment:
apt-get install python3-venv
python3.11 -m venv /opt/openwebui
We activate the environment
source /opt/openwebui/bin/activate
We install open-webui, which will take a while depending on your connection.
pip install open-webui
Once it finishes, we start open-webui
open-webui serve
And we access it through the url http://localhost:8080/ or, as in our case, since it is on another machine, http://192.168.1.85:8080

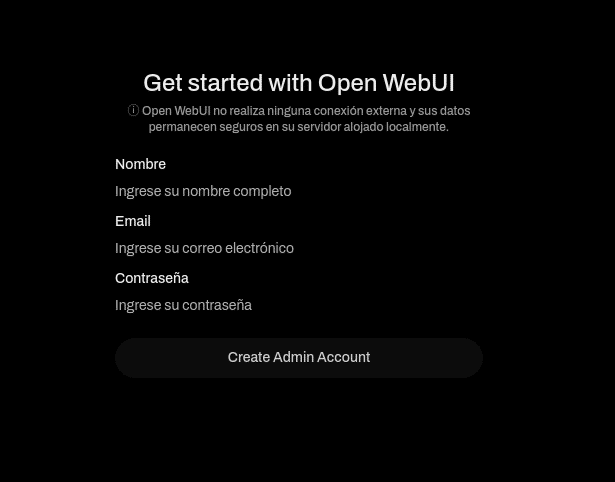
And we start the wizard
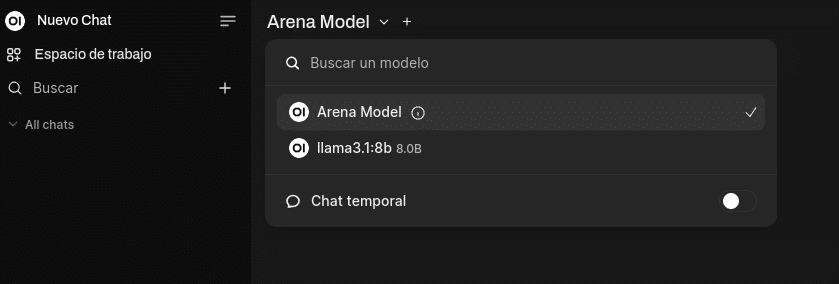
Once you are inside, you will see that we have the default model and our llama3.1:8b, since it is on the default port 11434 on the same machine
If our Ollama server were on another machine, we would have to add it in Configuration/Administrator Configuration
And inside connections, where we can also configure OpenAI with your API key, taking into account that it has a cost.
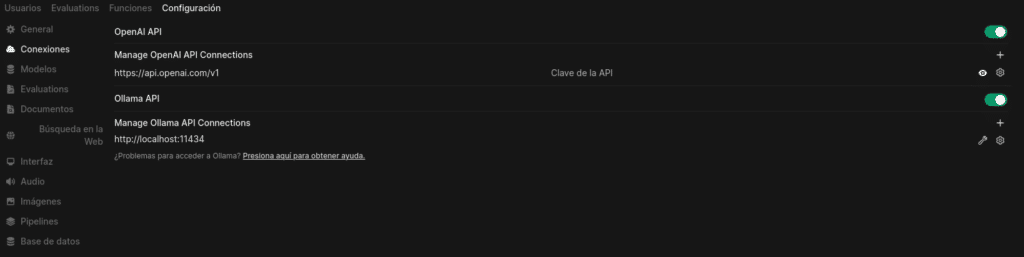
Disable it if you are not going to use it so that it does not try to query OpenAI because if it is enabled it will try to do so giving 500 errors in your log.

This is just the beginning of a very wide world.
TL.